- Published: 2024-05-09
- Keywords: Computer Science - Artificial Intelligence,Computer Science - Human-Computer Interaction
- URL: http://arxiv.org/abs/2405.08007
- BibTeX: @jonesPeopleCannotDistinguish2024
Reading Status
Abstract
We evaluated 3 systems (ELIZA, GPT-3.5 and GPT-4) in a randomized, controlled, and preregistered Turing test. Human participants had a 5 minute conversation with either a human or an AI, and judged whether or not they thought their interlocutor was human. GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%). The results provide the first robust empirical demonstration that any artificial system passes an interactive 2-player Turing test. The results have implications for debates around machine intelligence and, more urgently, suggest that deception by current AI systems may go undetected. Analysis of participants’ strategies and reasoning suggests that stylistic and socio-emotional factors play a larger role in passing the Turing test than traditional notions of intelligence.
Twitter Thread
By one of the authors: https://twitter.com/camrobjones/status/1790766472458903926?t=JC3LXH3WnFXNX79DrVisGQ
Notes
Study Overview
The research assesses ELIZA, GPT-3.5, and GPT-4 in a randomized, controlled Turing test. Participants engaged in 5-minute conversations and identified their interlocutors as either human or AI.
Results
- GPT-4 was identified as human 54% of the time.
- ELIZA was identified as human 22% of the time.
- Actual humans were correctly identified 67% of the time.
Implications
These findings highlight GPT-4’s advanced conversational abilities, though it still lags behind actual humans. The study suggests that stylistic and socio-emotional factors are crucial in passing the Turing test.
The figure below shows all the strategies used by participants to identify the AI:
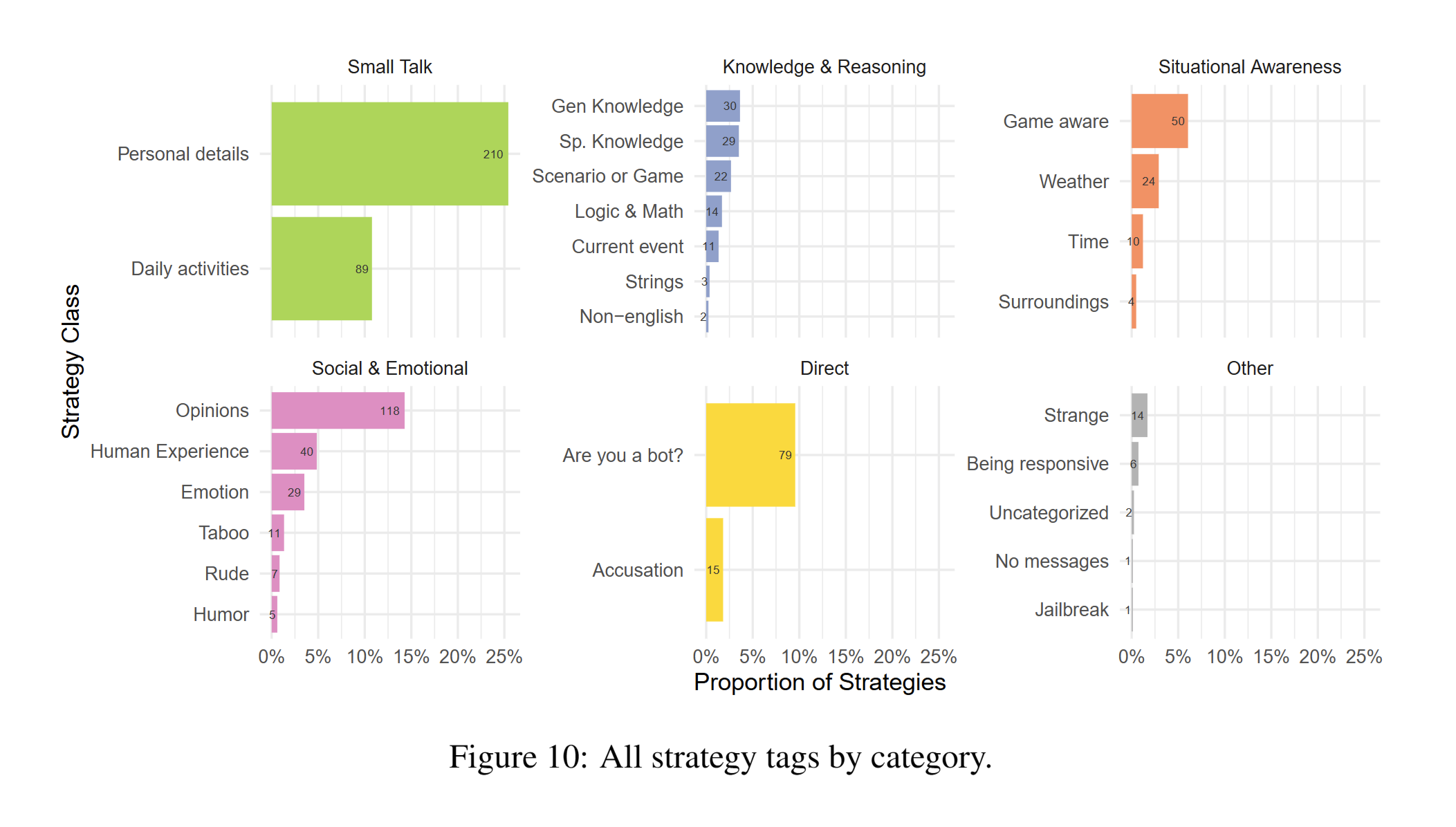
Personal Notes
- I find the method used in the study somewhat unusual and have doubts about the results. It’s relatively easy to distinguish an AI from a human by applying jailbreak techniques or focusing on knowledge areas.
- A language model typically possesses extensive knowledge across various fields, allowing it to respond in multiple languages or provide code, bypassing prompt restrictions easily.
- Querying the model on diverse subjects can reveal its vast knowledge base, which an average human wouldn’t have.
- I have trouble believing these results. The percentages could still be explained by random guessing.
- If these findings are more robust than I think, it indicates a lack of education and practical use of these language models in the general population.
- It always has been easy to bamboozle with “intelligence” stuff: the mechanical turk, Clever Hans, etc.